Home » Useful Articles »
eScraper Smart Scan feature – extract product data with automatic fields detection

Do you need to import products from any site, and you do not have a CSV file? In this article we will show you how to use eScraper Smart Scan feature to extract product data from any URL into a CSV file.
With the help of eScraper and Smart Scan feature you can automatically detect products and scrape the most common product fields, like: name, price, sku, description, images and other fields into .csv file without any technical skills.
So, in order to scrape data from any site you need to follow few steps:
- Install eScraper app, free trial version
- Run the application and use Create a new scan option
- Specify the product URL from the site that you would like to scrape and hit OK
- Check the fields that eScraper detected automatically
- Run the scrape. Here you can track the scraping process. Take your time
- Save the file with data extracted from the site and check the result
Let’s go through the steps one-by-one.
1. Install eScraper app, free trial version
Install eScraper free trial version. Here you can find the download link. Please note, the free trial version allows you to scrape up to 100 products. You can find both free trial and paid plans here.
2. Run the application and use Create a new scan option
On the first run you will see an option to create a new scan. The “Create new” option allows you to detect fields to scrape automatically without any manual configuration or technical skills with the help of Smart Scan. Use this option to proceed.

Run eScraper and choose Create new to use Smart Scan
Import option allows you to upload previously configured scrapes. If you have a configuration provided by a support team, you’re welcome to load it here.
3. Specify the product URL from the site that you would like to scrape and hit OK
On the next step you need to specify the product URL from the site that you would like to scrape. It is important to specify product URL. If you specify homepage URL, eScraper will not be able to detect product fields automatically.
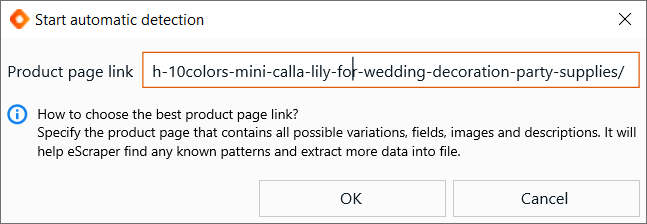
Create new configuration by specifying the product URL
It is a good idea to find the product that contains variations, prices, and all data that you need to scrape, to make sure our automatic scan can detect all possible fields.
In case you receive empty file or some fields were not detected, please check the product URL once again and make sure it is accessible via URl.
4. Check the fields that eScraper detected automatically
On this step you can check the fields that eScraper have detected. You can proceed with the scrape by clicking OK.
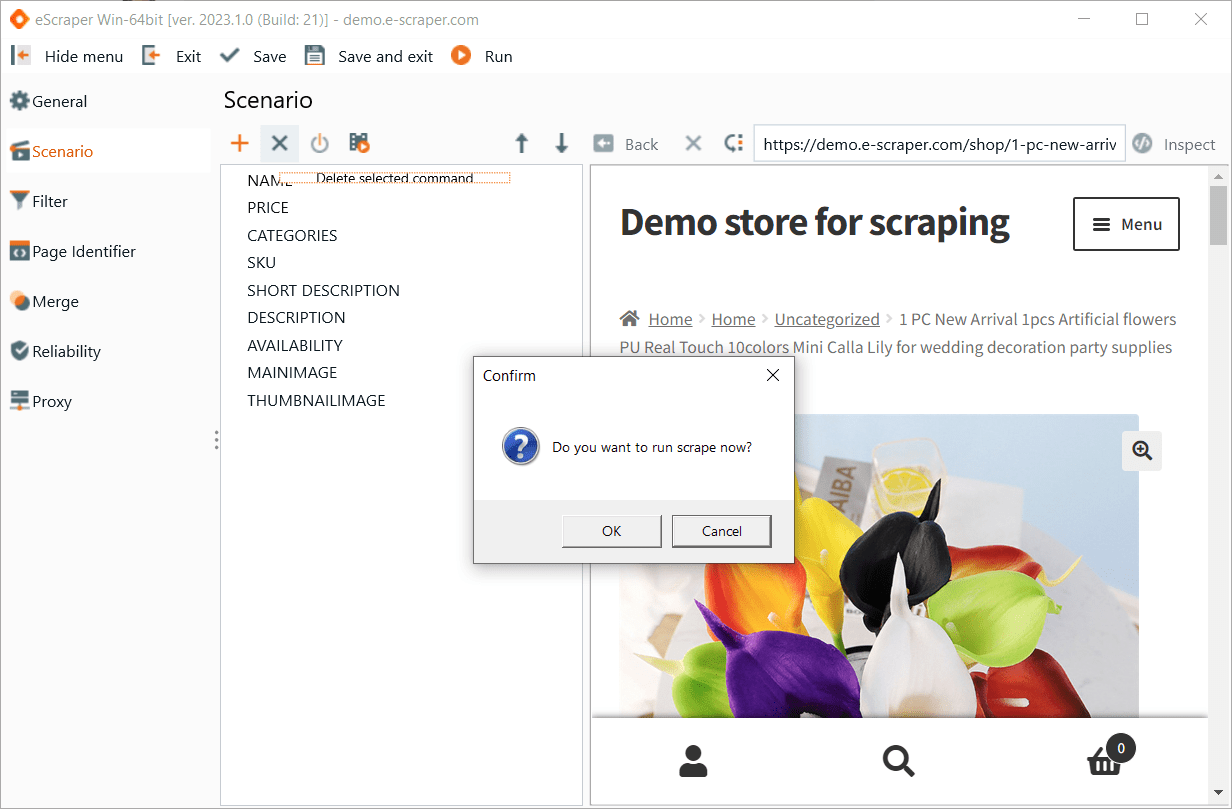
Automatically detected fields for automated product data extraction
Important! If the site that you’re scraping contains any banner or blocking window, or if you need to login, you can use the right pane browser and apply the change that is required to proceed.
Also here you can see the list of fields that eScraper have detected. The list of fields can contain:
- product name,
- price,
- long description,
- short description,
- categories,
- SKU,
- availability,
- images,
- and other product fields.
If you can see all fields that you need to scrape, hit Ok to proceed
5. Run the scrape. Here you can track the scraping process. Take your time
It may take some time to scrape the whole site. It is a good idea to stop the scrape as soon as few products were detected and data scraped. This way you will be able to check the result without having to wait till the whole scraping process ends.
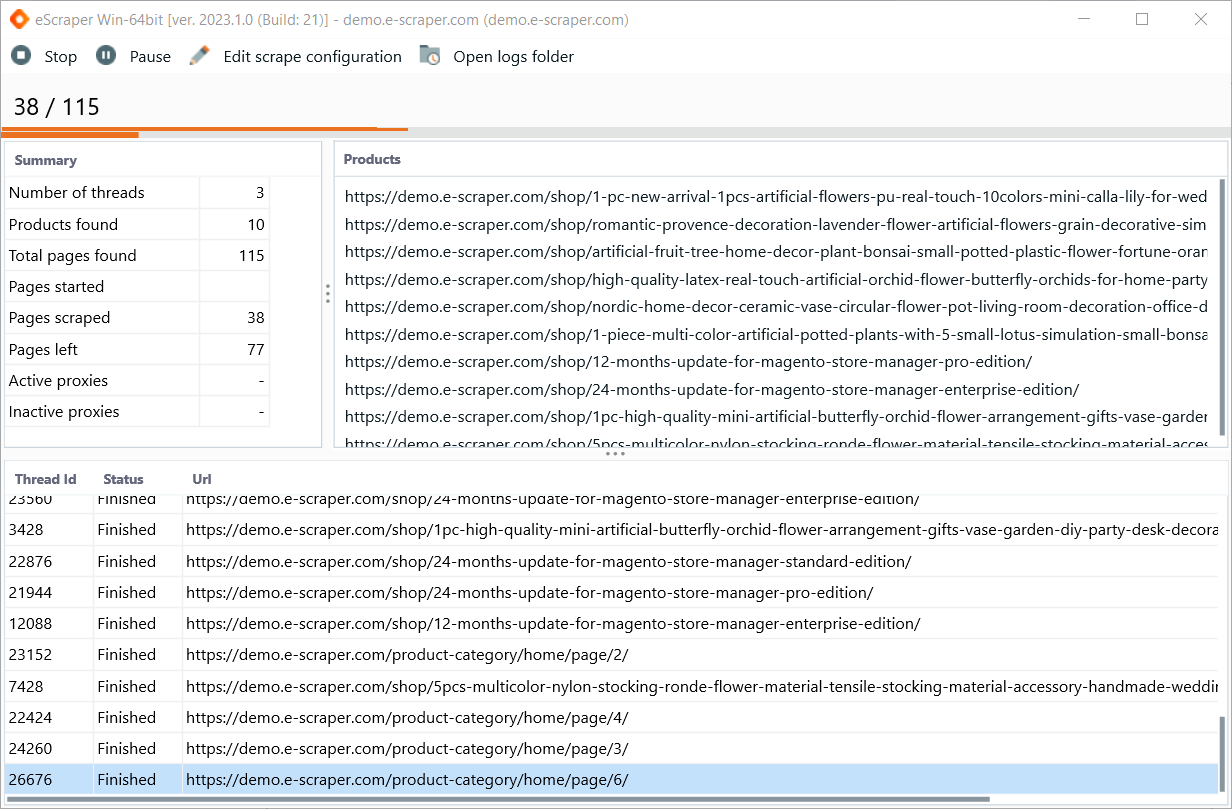
Product data extraction process
On this step you can find the data extraction summary. It allows you to track the process real time. So here you can find:
- The number of threads that you’re currently using – the number is adjustable, but we would not recommend using a large number of treads to avoid site overload.
- The number of products found at the moment. If the number is not increased, most likely there are no more products on the website, or that eScraper Smart Scan could not detect any products. Contact us for assistance in case there are no products found.
- Total pages found – the list of products that will be scraped, this includes category pages, filters and other pages where eScraper is looking for products.
- Pages scraped provides you with the number of pages that eScraper have checked already. This includes category pages, product pages, homepage, etc.
- Pages left – here you can see how may pages eScraper have detected already. If this number is not increased any more, that means that no furhter pages are found. Wait for the progress so all the pages left become Pages scraped and save the file to get the products data from whole site scraped.
- Information about proxies. You will be able to see this information if you’re configuring a custom scrape.
Wait till the scrape is finished, or you can stop the scrape and save the extracted data into a .csv file.
6. Save the file with data extracted from the site and check the result
Check the result file with the data scraped from the site that you have provided.
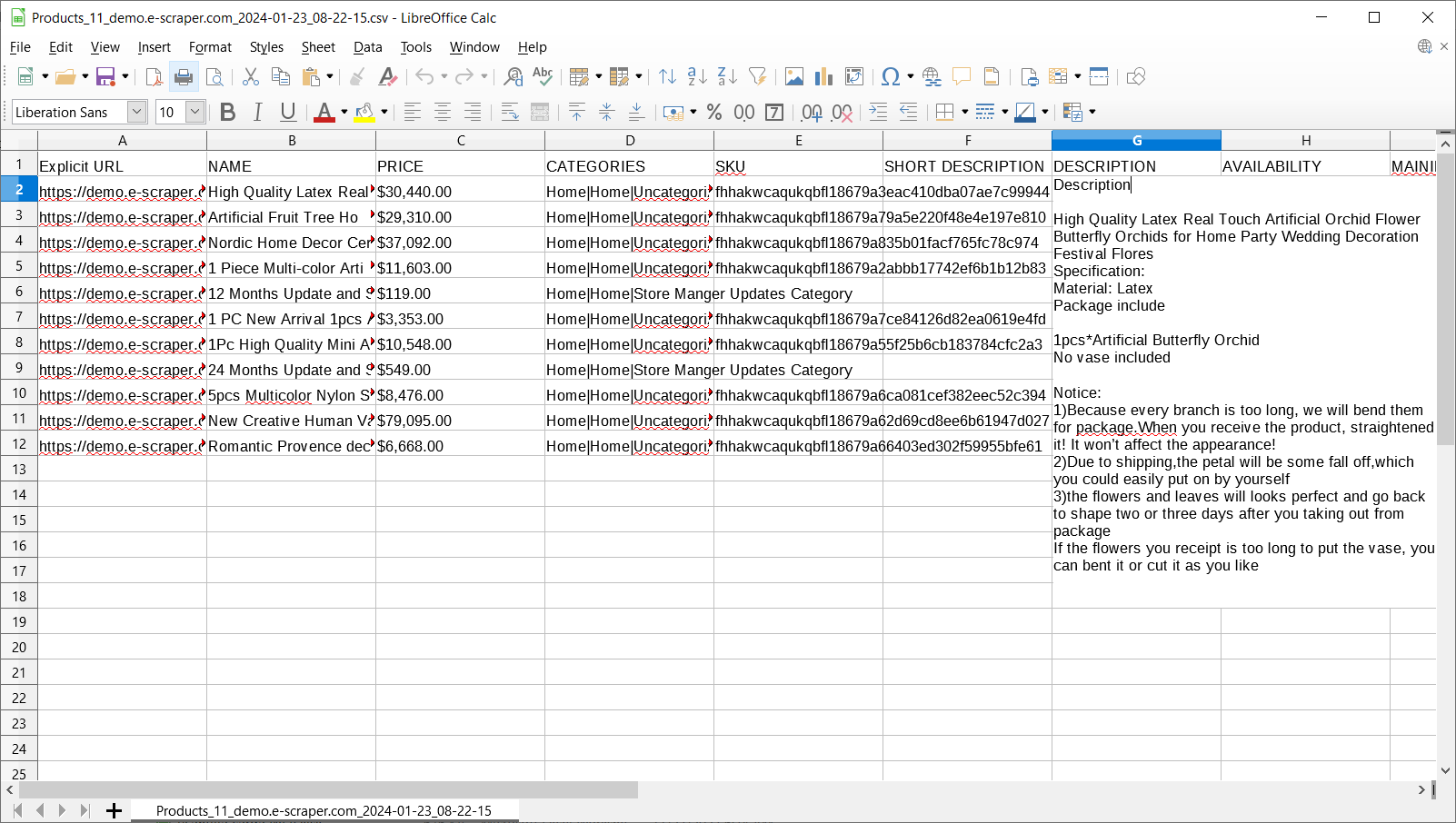
Result file
In case you would like to import the file, you should carefully check all rows and columns to make sure all data is accurate and available.
Also it is a good idea to open the product URL using the link from the first column and check if all values were extracted into file correctly.
In case you need any additional fields, variations, or if your file is empty, contact eScraper support team, and they will assist you with the configuration free of charge.
Do not hesitate to download the free trial version and check eScraper Smart Scan feature!
